
About Me
I graduated with Ph.D. from UIUC in May 2020. Please visit my LinkedIn page about my post-Ph.D. adventures. I intend to keep this website for my Ph.D. journey only. :)
I was a Ph.D. student in the Database and Information Systems Lab of Computer Science Department at the University of Illinois (UIUC), working with Professor Aditya Parameswaran. My research focuses on designing systems and techniques to accelerate large-scale data analytics, ranging from tasks on a single large dataset to the massive number of versions of a dataset stored on multiple third-party data sources.
I obtained my B.S. degress in Computer Science and Mathematics from University of Wisconsin, Madison in 2015 (Go Badgers!). Before I came to the U.S., I studied at Nanjing Foreign Language School, China.
Publications
Learning to Optimize Federated Queries
Liqi Xu, Richard L. Cole, Daniel Ting
Exploiting Artificial Intelligence Techniques for Data Management (aiDM) Workshop at International Conference on Management of Data (SIGMOD)
Amsterdam, The Netherlands. June 2019
Query optimization is challenging for any database system, even with a clear understanding of its inner workings. Consider then, query planning for a federation of third-party data sources where little detail is known. This is exactly the challenge of orchestrating data execution and movement faced by Tableau’s cross-database joins feature, where the data of a query originates from two or more data sources. In this paper, we present our work on using machine learning techniques to address one of the most fundamental challenges in federated query optimization: the dynamic designation of a federation engine. Our machine learning model learns the performance and data characteristics of a system by extracting features from query plans. We further extend the ability of our model to manipulate database settings on a per query level. Our experimental results demonstrate that we can achieve a speedup of up to 10.7× compared to an existing federated query optimizer.
Optimally Leveraging Density and Locality for Exploratory Browsing and Sampling
Albert Kim*, Liqi Xu*, Tarique Siddiqui, Silu Huang, Samuel Madden, Aditya Parameswaran
Human-in-the-loop Data Analytics (HILDA) Workshop at International Conference on Management of Data (SIGMOD)
Houston, USA. June 2018
(* Equal Contribution)
Exploratory data analysis often involves repeatedly browsing a small sample of records that satisfy certain predicates. We propose a fast query evaluation engine, called NeedleTail, aimed at letting analysts browse a subset of the query result on large datasets as quickly as possible, independent of the overall size of the result. NeedleTail introduces DensityMaps, a lightweight in-memory indexing structure, and a set of efficient and theoretically sound algorithms to quickly locate promising blocks, trading off locality and density. In settings where the samples are used to compute aggregates, we extend techniques from survey sampling to mitigate the bias in our samples. Our experimental results demonstrate that NeedleTail returns results 7× faster on average on HDDs while occupying up to 23× less memory than existing techniques.

DataDiff: User-Interpretable Data Transformation Summaries for Collaborative Data Analysis
Gunce Yilmaz, Tana Wattanawaroon, Liqi Xu, Abhishek Nigam, Aaron Elmore, Aditya Parameswaran
International Conference on Management of Data (SIGMOD), Houston, USA. June 2018
Interest in collaborative dataset versioning has emerged due to complex, ad-hoc, and collaborative nature of data science, and the need to record and reason about data at various stages of pre-processing, cleaning, and analysis. To support effective collaborative dataset versioning, one critical operation is differentiation: to succinctly describe what has changed from one dataset to the next. Differentiation, or diffing, allows users to understand changes between two versions, to better understand the evolution process, or to support effective merging or conflict detection across versions. We demonstrate DataDiff, a practical and concise data-diff tool that provides human-interpretable explanations of changes between datasets without reliance on the operations that led to the changes
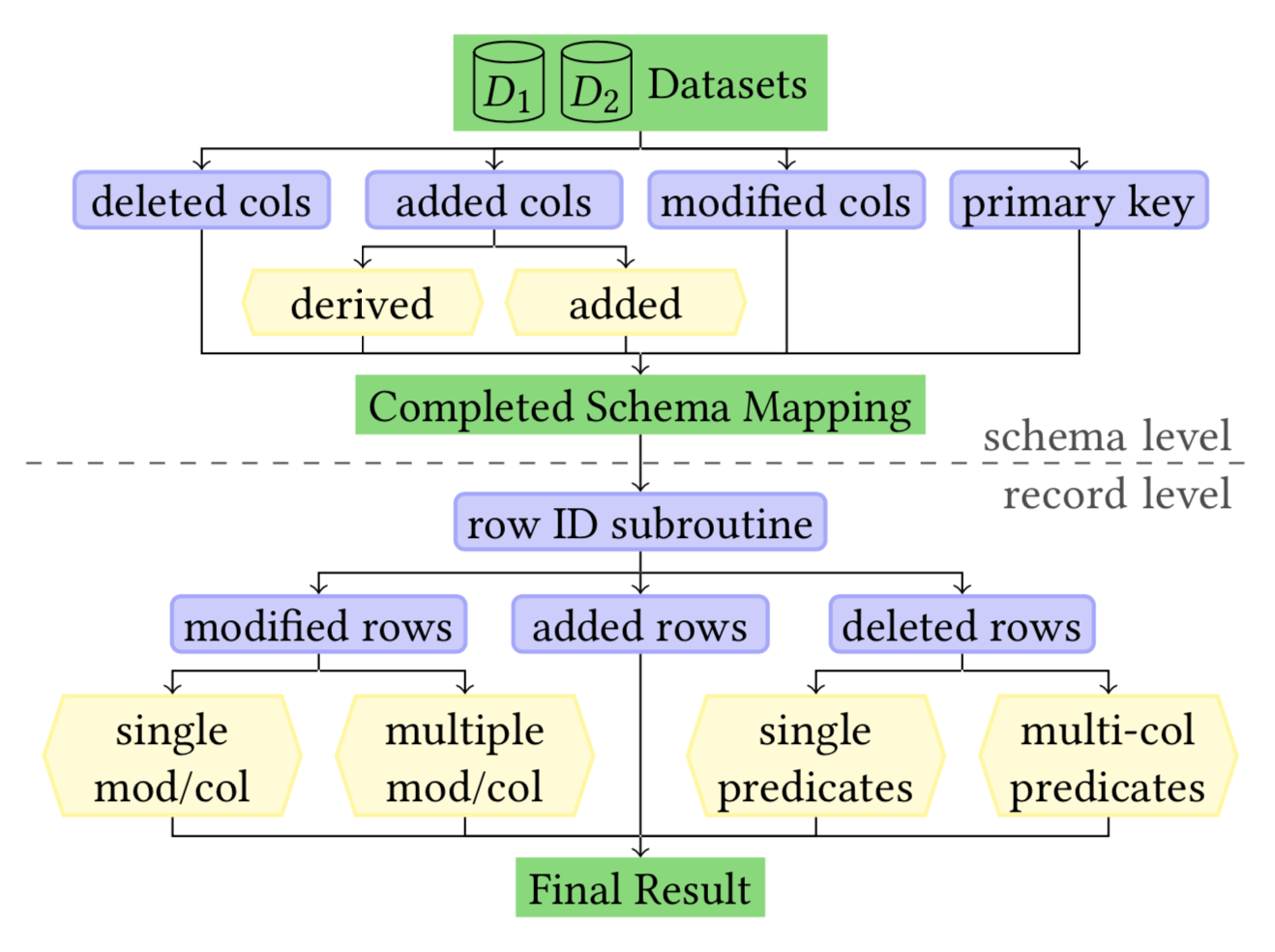
OrpheusDB: Bolt-on Versioning for Relational Databases
Silu Huang, Liqi Xu, Jialin Liu, Aaron Elmore, Aditya Parameswaran
43rd International Conference on Very Large Data Bases (VLDB), Munich, Germany. September, 2017
(Invited to: Special Issue of VLDB Journal for VLDB 2017 Best Papers)
Data science teams often collaboratively analyze datasets, generating dataset versions at each stage of iterative exploration and analysis. There is a pressing need for a system that can support dataset versioning, enabling such teams to efficiently store, track, and query across dataset versions. While git and svn are highly effective at managing code, they are not capable of managing large unordered structured datasets efficiently, nor do they support analytic (SQL) queries on such datasets. We introduce OrpheusDB, a dataset version control system that “bolts on” versioning capabilities to a traditional relational database system, thereby gaining the analytics capabilities of the database “for free”, while the database itself is unaware of the presence of dataset versions. We develop and evaluate multiple data models for representing versioned data, as well as a light-weight partitioning scheme, Lyresplit, to further optimize the models for reduced query latencies. With Lyresplit, OrpheusDB is on average 103× faster in finding effective (and better) partitionings than competing approaches, while also reducing the latency of version retrieval by up to 20× relative to schemes without partitioning. Lyresplit can be applied in an online fashion as new versions are added, alongside an intelligent migration scheme that reduces migration time by 10× on average.

OrpheusDB: A Lightweight Approach to Relational Dataset Versioning
Liqi Xu, Silu Huang, Sili Hui, Aaron Elmore, Aditya Parameswaran
International Conference on Management of Data (SIGMOD), Chicago, USA. June, 2017
(Best Demo Honorable Mention)
We demonstrate OrpheusDB, a lightweight approach to versioning of relational datasets. OrpheusDB is built as a thin layer on top of standard relational databases, and therefore inherits much of their benefits while also compactly storing, tracking, and recreating dataset versions on demand. OrpheusDB also supports a range of querying modalities spanning both SQL and git-style version commands. Conference attendees will be able to interact with OrpheusDB via an interactive version browser interface. The demo will highlight underlying design decisions of OrpheusDB, and provide an understanding of how OrpheusDB translates versioning commands into commands understood by a database sys- tem that is unaware of the presence of versions. OrpheusDB has been developed as open-source software; code is available at http://orpheus-db.github.io.

An Empirical Evaluation of Machine Learning Approaches for Angry Birds
Anjali Narayan-Chen, Liqi Xu, Jude Shavlik
International Joint Conference on Artificial Intelligence (IJCAI) Symposium on AI in Angry Birds, Beijing, China. August, 2013
(Advanced to the final rounds as the only undergrad team)
(Won the 3rd Place in the 2013 Angry Birds AI Competition at IJCAI)
Angry Birds is a popular video game in which players shoot birds at pigs and other objects. Because of complexities in Angry Birds, such as continuously-valued features, sequential decision making, and the inherent randomness of the physics engine, learning to play Angry Birds intelligently presents a difficult challenge for machine learning. We describe how we used the Weighted Majority Algorithm and Naive Bayesian Networks to learn how to judge possible shots. A major goal of ours is to design an approach that learns the general task of playing Angry Birds rather than learning how to play specific levels. A key aspect of our design is that the features provided to the learning algorithms are a function of the local neighborhood of a shot's expected impact point. To judge generality we evaluate the learning algorithms on game levels not seen during training. Our empirical study shows our learning approaches can play statistically significantly better than a baseline system provided by the organizers of the Angry Birds competition.
Industry and Teaching Experience
Data Science Intern | Microsoft | 2019 Summer
- Analyzed product usage using data collected via Local Differential Privacy (LDP), a data collection technique that protects privacy of individual users
- Estimated aggregate information and showed statistical significances between groups of LDPdata
- Used LDP data to identify limitations in the current pipeline and provided detailed and actionable future directions
- Manager: Paul Li
- Developed a machine learning approach to optimize federated queries
- Achieved a speedup of up to 10.7× compared to an existing federated query optimizer on real datasets
- Published the paper at aiDM workshop at SIGMOD 2019
- Mentors: Rick Cole, Daniel Ting
- CS101: Introduction to Programming for Engineers and Scientists | 2019 Fall, 2020 Spring
- Led 9 Teaching Assistants (grad students) and 15+ Course Assistants(undergrads) for a class with more than 700 students
- Instructor: Neal Davis
- CS101: Introduction to Programming for Engineers and Scientists | 2019 Spring
- Led two weekly two-hour labs; each lab consists of 40+ students
- Instructor: Neal Davis
- CS411: Database Systems | 2018 Spring
- Designed homeworks and exams and coordinated graders for a class of 200 students
- Instructor: Aditya Parameswaran
Awards
The Generation Google Scholarship | Google | 2014
The Grace Hopper Celebration (GHC) Scholarship | Palantir | 2014
Clarice Cox Scholarship | University of Wisconsin - Madison | 2014